Desarrollando microservicios con Nameko
Nameko es una biblioteca para el desarrollo de microservicios en Python. A diferencia de otros frameworks como Django, Flask y Hug que tienen como principal objetivo utilizar HTTP para la comunicación con los clientes, Nameko viene con soporte integrado para AMQP y Websockets y nos permite adicionar nuestros propios protocolos.
Manos a la obra.
Para hacer servicios con Nameko necesitamos algunas cosas:
- Python 2 (creo que no hay versiones para Python 3).
- Un entorno virtual (
virtualenv). - La biblioteca (vía
pippara garantizar las dependencias). - RabbitMQ u otro servidor de mensajería que soporte AMQP.
- Emacs (o tu editor favorito).
Creemos dos servicios:
- Servicio que hace una operación intensiva (sumar dos números) al que llamamos
Calculate - Servicio que nos notifica cuando
Calculatetermina, al que llamamosNotify.
from nameko.rpc import rpc, RpcProxy
import logging
class Compute(object):
name ="compute"
notify = RpcProxy("notify")
@rpc
def method(self, value1, value2):
a = value1 + value2
self.notify.send.call_async("Operation completed %s" % a)
return a
class Notify(object):
name ="notify"
logger = logging.getLogger(__name__)
@rpc
def send(self,message):
self.logger.info(message)
Salvemos el archivo como services.py y ya estamos listos para ejecutar los servicios
$ nameko run --broker pyamqp://guest:guest@localhost services
Si accedemos a la consola web de RabbitMQ podemos ver las colas de mensaje creadas para los servicios. Eso confirma que se están funcionando correctamente.
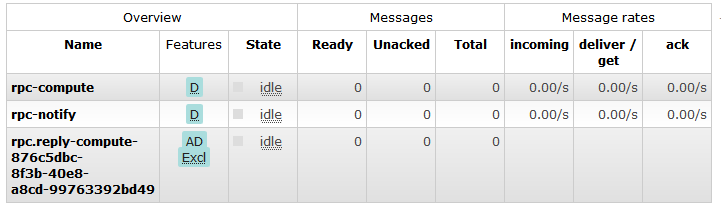
Accediendo a los servicios.
Antes de desplegar nuestros servicios en producción, probemos que funcionan correctamente. Desafortunadamente fuimos demasiado rápido y no creamos pruebas unitarias (muy mal de nuestra parte) así que necesitamos alguna forma de verificar que las interfaces hagan lo planeado (este concepto de suma es aparentemente muy complicado).
Por suerte Nameko nos proporciona un REPL mediante el comando shell
que nos permite interactuar con los servicios desde código Python.
nameko shell --broker pyamqp://guest:guest@192.168.184.142
Nameko Python 2.7.13 [MSC v.1500 64 bit (AMD64)] shell
Broker: pyamqp://guest:guest@192.168.184.142
>>> n.rpc.compute.method(99999,99999)
199998
>>> reply=n.rpc.compute.method.call_async(99999,99999)
>>> reply.result()
199998
>>>
Perfecto, funcionan tanto las llamadas síncronas como las asíncronas, con esto en mano podemos utilizar los servicios desde, por ejemplo, un modelo en Odoo.
from nameko.standalone.rpc import ClusterRpcProxy
BROKER ='pyamqp://guest:guest@192.168.184.142'
# Todas las cosas del modelo....
@api.multi
def action_suma(self):
val1 = self.campo_1
val2 = self.campo_2
with ClusterRpcProxy(BROKER) as rpc:
self.val3 = rpc.compute.method(val1,val2)
Gracias a que RabbitMQ actúa como broker y registro de los servicios, podemos desplegar tantos como queramos, el consumidor no necesita saber donde están localizados, ni cuantos son, como un plus, los servicios se pueden añadir dinámicamente a al cluster
Adicionando un hearbeat.
Nuestros servicios funcionan, es hora de desplegarlos en producción, pero el sysadmin se queja de que no tiene forma de monitorear el estado de los mismos. Aunque estamos absolutamente seguros de que nuestros servicios tienen un 100% de disponibilidad, para complacerlos adicionamos un hearbeat que se ejecute cada un tiempo configurable en cada una de las instancias.
from nameko.timer import timer
# Método ficticio que envía un mensaje a la plataforma
# de monitoreo.
from monitoring import ping
class Heartbear(object):
name="heartbeat"
@timer
def beat(self):
ping()
Más de Nameko.
Además de RPC vía AMQP, Nameko proporciona facilidades para crear
Web APIs, notificación de eventos entre servicios, integración con
Django, Flask, SQLAlchemy y permite crear nuestros propios puntos de
entrada para servicio (ya hemos visto @rpc y @timer). En lo particular lo
considero una alternativa interesante y rápida que necesita pocas dependencias
tanto para desarrollo como para despliegue. Si estás interesado puedes consultar
la documentación oficial.